Migrating our production deployment from MariaDB Galera to PostgreSQL and Patroni
This night, pretix.eu had a planned outage for around 70 minutes to allow us to make a fundamental change to our service architecture. In this blogpost, we want to go into detail on what we changed and why. We hope this might be insightful for you if you run a similar service or if you are just curious about the challenges we experience along the way.
General overview
The main deployment of pretix, pretix.eu, has a scale that would – with some engineering efforts – probably be able to run from a single high-end dedicated server without major trouble. We’re not Instagram-scale and we’re unlikely to be very soon. Running pretix on a single machine would be much simpler and easier than what we do – but has a very harsh drawback: Servers tend to fail. When running of a single machine, we would be completely out of business with every hard- or software failure of that server.
Therefore, pretix.eu is hosted in a cluster of nodes (currently nine virtual machines) that are designed in a way that in theory every single node can fail at any time without impacting the availability of the system. Since our team is too small to operate a 24/7 on-call schedule, it is important to us that the system can also automatically recover quickly from any such failure, at least in a way that keeps the system running until a human can have a deeper look and clean things up.
pretix itself is a Django application that runs as a webserver in a stateless manner – no important state is ever stored within the application’s memory. Therefore it is quite easy to run the code on multiple nodes in parallel and just have nodes fail at times. The only thing needed to make this seamless for users is a load balancer in front that takes all incoming HTTP requests, terminates the SSL connection and forwards the request to an application worker node that is currently alive. Additionally, the app nodes run Celery-based worker processes that work on longer-running background tasks (like sending e-mail or generating data exports).
We use haproxy as a loadbalancer and to allow our haproxy setup to fail as well, we of course need two of them. Our
domain name pretix.eu has two A/AAAA DNS records listing the two load balancer servers. Your browser is usually
clever enough to use the working IP address if the other one is not working.
So far, this is a very simple setup, which only gets worse because we unfortunately need to store lots of important data: Events, settings, ticket orders, invoices, etc. Storing data is stateful by definition and therefore notoriously hard to do in a way that satisfies our availability needs.
pretix makes use of two different types of data stores:
-
A relational database, used for storing persistant application data
-
A high-performance key-value-store used for short-lived data (caching, sessions, …)
To complete the picture, some kind of task queue is required to schedule background tasks and coordinate the Celery processes. It is a hard fact that you can only have a safe, distributed system that allows for failure of a single node while staying fully functional if you have at least three nodes, so we have three database nodes.
Our old setup
For the first years of operation, we used MariaDB (a community fork of MySQL) as our relational database. There were two main reasons for choosing MariaDB:
-
I’ve personally been working with MySQL for more than eleven years now. After all this time, many of its quirks just come natural to me and I feel confident fixing a problem when awoken in the middle of the night by a monitoring alert.
-
With Galera clusters, MariaDB provides an easy-to-use way to set up Master-Master replication. At the time, it seemed like the best option to get both a high availability and high confidence in write durability.
As a key-value-store, we’ve been using Redis since the beginning and RabbitMQ as a queue server. Both of them have native functionality (Redis Sentinels and Erlang clusters) to create high-availability clusters.
Here’s the old setup in a quickly-drawn picture for your convenience:
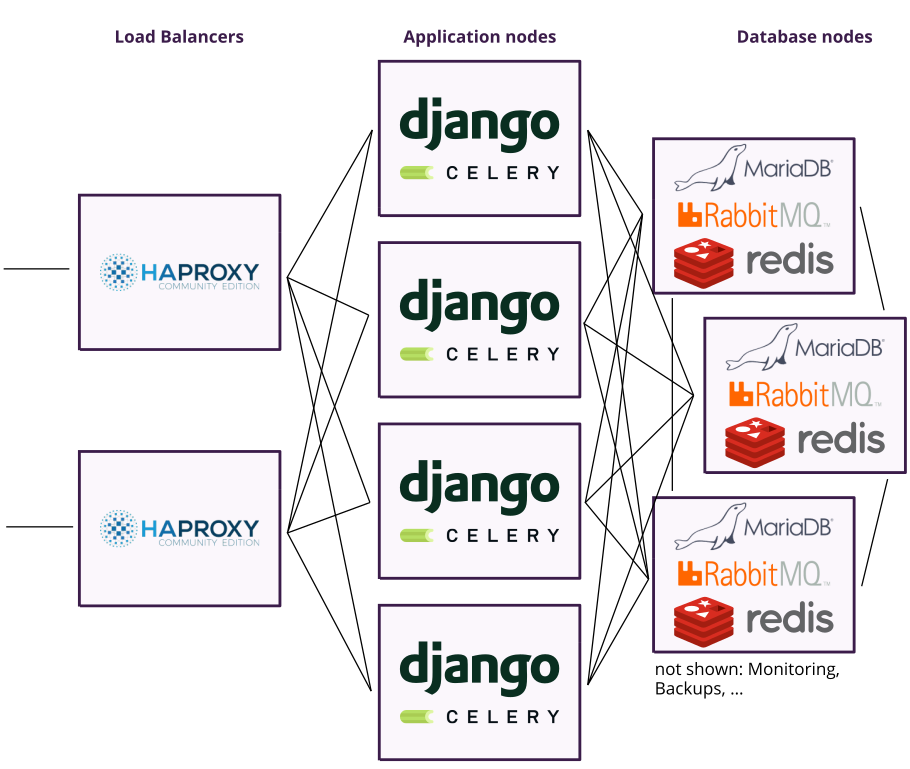
This is still a simplified description. In reality, an additional instance of HAProxy (not shown in the picture) is deployed to every application node with the purpose of redirecting connection attempts to MariaDB, RabbitMQ or Redis only to available database nodes (and in case of Redis, only to the leader since followers do not accept writes). Also, we run multiple Celery worker processes per node in order to distribute load between different queues (to avoid the checkout queue being spammed by email tasks etc) and we ignore the matter of generated and user-uploaded files in this blogpost alltogether, this will be a story for another day.
After more than a year of practical experience with the setup, we learned a lot about its strengths and problems:
Advantages
-
MariaDB Galera is really easy to set up and maintain. You need to write very little configuration for the nodes to discover themselves and Galera can automatically recover from nearly all failures that we experienced. Nodes that have been offline recover reliably and re-join the cluster automatically.
-
Since multiple masters are operating at the same time, no explicit failover is needed to take a node out. This allows for reboots or software updates of any single node without any noticable service disruption for end users.
-
Both of these previous reasons lead to a very high overall uptime of the database cluster. We did have some downtimes over time, but nearly none of them have been caused by the MariaDB cluster.
Disadvantages
-
Even in completely normal non-busy operation, some nodes often lagged behind others, leading incoming requests to fail because queries returned errors like
WSREP has not yet prepared node for application use. This happened on a near-daily basis. -
Multiple times a day, requests failed because of deadlocks in the database system. This naturally affected mostly requests which are critical to the functionality of the system and is an expected side-effect of multi-master setups. We might have been able to reduce their occurance, but MariaDB doesn’t make it easy to debug them and over time, we just got tired to see the exception message
Deadlock found when trying to get lock; try restarting transaction. -
Performance was very bad on some important queries that operate on large database tables, e.g. the search for a specific order. For some of our customers who have access to tens of thousands of sold tickets, some pages took up to 30 seconds to load (or timed out). We spent a large amount of time investigating these queries and how MariaDB executes them. Some of them would be trivially easy to optimize with the correct indices – however, MariaDB has a hard limit of using one index per table in a single query. If we already need to use that to only select orders from the correct event, good luck optimizing the selection of orders within that event. (Some MySQL DBAs might argue that we need to change our schema, but as an application developer, I strongly disagree, the schema should model the problem domain and not the database quirks.)
-
We needed to take additional performance drawbacks to get rid of problems with dirty reads.
-
We talked to a few database experts at the side of one or two conferences and this made us lose any trust that Galera is able to perform even remotely well in terms transaction isolation, constraint enforcement, etc., even though we did not observe such problems in practice ourselves.
Our new setup
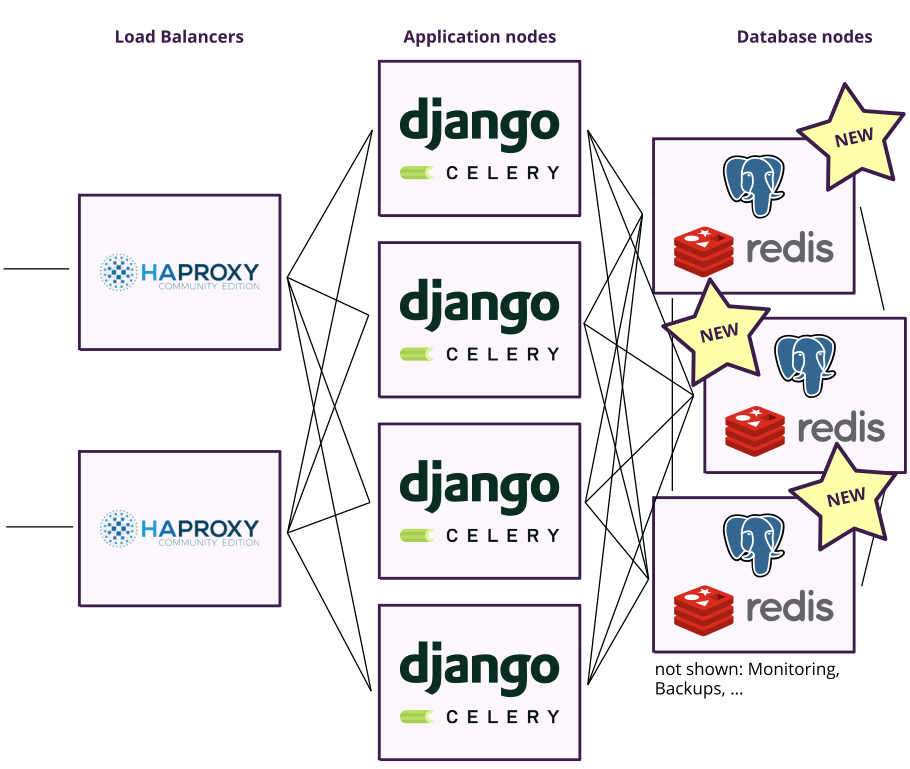
Last night, we basically executed three major changes: First, we switched our database from MariaDB to PostgreSQL for the reasons listed above.
Second, we removed RabbitMQ completely. While RabbitMQ only once created a problems in practice, the cluster management is really nasty to get right and it introduces more complexity than we really need. For our purposes, it is completely sufficient to use our Redis instance as a Celery task broker as well. RabbitMQ can do great things that Redis can’t, but we don’t make use of any of them and there is no measurable performance difference in our case.
Third, we set up PostgreSQL together with a new Redis cluster on a new set of nodes with twice as much RAM and CPU power as the old ones.
Here is the new overview:
PostgreSQL High-Availability
You might now ask yourself how we achieve high-availability with PostgreSQL in a similar way than with MySQL, and even though there are ways to do multi-leader replication with PostgreSQL, the short answer is: We don’t. We have not been able to find a solution that has similar availability properties as Galera and at the same time is simple to maintain.
We decided that we can live with a solution that has a few drawbacks with regards to failover times etc., but is simple, fast and values data consistency. A comparison of multiple solutions lead us to Patroni, a blueprint for high-available PostgreSQL deployments developed at Zalando. In simple words, patroni is a small daemon that supervises and orchestrates PostgreSQL instances by monitoring their status and rewriting their configuration and restarting them when necessary. Under the hood, patroni is written in Python and makes use of a distributed configuration store like etcd that already robustly implements distributed consensus for leader election.
During evaluation, we tested Patroni on a number of AWS Spot Instances and simulated various kinds of outages and found that it satisfies our tradeoff between reliability, simplicity and availability quite well, even though it has some disadvantages.
Advantages
-
In our first tests it really is a lot faster. This is in no way a fair benchmark since we’re now also running on stronger hardware than before and we haven’t tested with real user load, but I believe this is not the only reason. We haven’t specifically optimized any single query for PostgreSQL yet, but while it has been basically impossible to search all orders in the system for a name in less than 30 seconds, it now takes 800 milliseconds. We call that a success ;)
-
With Patroni, at any given time there is only one database leader in charge of all writes. Even though this reduces the theoretical parallelization opportunities, it probably is a performance gain in practice since locks only need to happen within a single node and latency is removed. Also, we do not need to rely on any consensus algorithms or distributed lock mechanisms for data consistency but only need to rely on standard PostgreSQL, which has been tested for decades and has a very good reputation for its quality.
-
It is possible to state that one of the two follower nodes should be used for synchronous replication, making sure that all confirmed writes are persisted to two different systems. This obviously re-introduces some of downsides with regards to latency.
-
In recent times, Django added more and more features that make use of advanced, PostgreSQL-specific database features. Many of them would be useful for us as well. Although we currently do not have any plans to deprecate support for other databases in pretix (mostly because we really want to keep SQLite for development and testing), it is a possible future and a migration will certainly not get easier with more data and customers.
Disadvantages
-
Since only one leader is active at the same time, the system turns unavailable as soon as this leader goes offline until a new leader has been elected. This means that in case of both manual and automatic failover, depending on conditions and configuration, the service will be down for 30-60 seconds. This is not great and we’ll look into tuning these timeouts further, but it is still orders of magnitude better than anything relying on manual failover and a downtime of 30 seconds doesn’t look great, but is acceptable, if it happens only when a server really fails or needs to be restarted, which isn’t that often.
-
Although patroni is in use at some large-scale organizations like Zalando, it is a bit unclear how battle-tested and fireproof it is. However, since patroni only manages orchestration of PostgreSQL instances, it will always be possible to move to other options like repmgr without the need for another major data migration.
-
Follower nodes reply to read queries even if they know that they are greatly out of sync. This is unacceptable to us for most queries since we need to make decisions on current data, which is why we currently really only use the leader, even for reads. This feels like a waste of hardware, as two of three nodes are pretty bored most of the time. We would prefer if they’d block/fail if they know to be out of sync and use them for less-important read queries on other cases and are happy for any pointers.
The migration
After all this text on our reasoning and experiences, let’s get our hands dirty and dive into the technical details on how we did it. Before we start, let me stress that this is not a tutorial to be followed. If you ever attempt to do such a thing on your production, be sure to test it properly.
We tested the Patroni installation on a cluster of AWS Spot Instances before we installed it to the production nodes. Before we actually did the migration last night, we had fully performed the migration multiple times on our staging to make sure we’re doing it correctly and we also already performed many of the migration steps with production data to have a proper estimate on the duration it will take.
Migrating a Django database to PostgreSQL: Failed approaches
Migrating a real-world Django database to PostgreSQL is a lot more complicated than it first sounds. There are three simple approaches that come to mind and none of them works as intended:
-
Dump the data with Django’s
dumpdatamanagement command and load it withloaddata. While I’ve seen this approach work on moderately-sized SQLite→PostgreSQL migrations, it is not suitable for the database size at hand here. The tools are not really capable of handling the amount of data and they have major trouble dealing with some foreign key relationships, especially if they are circular. -
Any of the hundreds of migration tools that can migrate a complete database from MariaDB to PostgreSQL. MariaDB and PostgreSQL support different field types, constraints, etc., so each of these tools needs to do a complex and opinionated mapping of database structures. You will end up with a database structure that differs greatly from the one Django would have created on PostgreSQL, leading not only to a low-quality database scheme, but will also likely break any future migrations you want to apply on the database.
-
Creating the new Database structure with Django and then filling in the rows with a migration/data copy tool. Since PostgreSQL, unlike MariaDB, doesn’t allow you to easily skip foreign key constraints and other checks, this failed for us at many circular foreign keys or other consistency problems that can only be resolved after the import has been complete.
Migrating a Django database to PostgreSQL: Our working approach
In the end, we ended up with a quite complicated approach consisting of the following steps.
-
Create a PostgreSQL database, let’s call it
pretix_staging. In our internal documentation we always only refer to staging in order to make sure nobody accidentally copies a command and executes it on production ;) -
If the database is not empty, make sure to clean it up properly:
DROP SCHEMA public CASCADE; CREATE SCHEMA public; GRANT ALL ON SCHEMA public TO postgres; GRANT ALL ON SCHEMA public TO public; GRANT ALL ON SCHEMA public TO pretix_staging; -
Change the Django application (here:
pretix.cfg) to connect to the PostgreSQL database instead of your old MariaDB database and restart it. -
Apply migrations (
python -m pretix migrateordocker exec -it pretix-worker.service pretix migrate) to create the base database structure in the PostgreSQL database. -
Dump the created schema to a file:
postgres$ pg_dump -s -h 127.0.0.1 pretix_staging > schema.sql -
Clear the database of all tables again:
DROP SCHEMA public CASCADE; CREATE SCHEMA public; GRANT ALL ON SCHEMA public TO postgres; GRANT ALL ON SCHEMA public TO public; GRANT ALL ON SCHEMA public TO pretix_staging; -
Open your new file
schema.sqlwith a text editor. You will notice that it starts with thousands of lines of table definitions likeCREATE TABLE auth_group ( id integer NOT NULL, name character varying(80) NOT NULL );and series definitions like
ALTER TABLE ONLY pretixdroid_appconfiguration_items ALTER COLUMN id SET DEFAULT nextval('pretixdroid_appconfiguration_items_id_seq'::regclass);After these, it changes and starts to list all kinds of constraints:
ALTER TABLE ONLY auth_group ADD CONSTRAINT auth_group_name_key UNIQUE (name);Use your text editor to split the file into two: One file with all table and series definitions and one file with all constraints. Let’s call them
tables.sqlandconstraints.sql. -
Import only the tables into your database:
postgres$ psql -h 127.0.0.1 pretix_staging < tables.sql -
Use pgloader to migrate your data. Write a file with instructions like this (
staging.load):LOAD DATABASE FROM mysql://pretix_staging:***@mysql_host/pretix_staging INTO postgresql://127.0.0.1/pretix_staging WITH truncate, data only, disable triggers, preserve index names, include no drop, reset sequences ALTER SCHEMA 'pretix_staging' RENAME TO 'public';UPDATE: Make sure your server timezone is UTC at this point, or include a statement in this instruction file that sets the session timezone to UTC. Since MySQL doesn’t know or care about timezones, MySQL will (at least with Django) output UTC times as timezone-unaware datetimes and PostgreSQL will interpret them according to your session/server timezone. Please don’t ask how we fixed this when we found this out a day later (we did, without data loss, but it was nasty). Did I say you should do a backup before? :)
This will output some warnings like
WARNING Source column "public"."pretixbase_invoice"."id" is casted to type "bigserial" which is not the same as "integer", the type of current target database column "public"."pretixbase_invoice"."id".which are expected and can safely be ignored. It will then output a report of the number of rows copied per table and the amount it took. On our production system, it took 1min 45s to copy over 2.4 million database rows.
-
Import your constraint definitions
postgres$ psql -h 127.0.0.1 pretix_staging < constraints.sqlOn our production system, this took about 10 minutes.
Done! :)
The big daynight
After preparing this over the course of several months, we finally decided for Saturday, 2018-03-10, to be the night to perform the migration. On the Wednesday before, we notified all active customers (= all customers with an active account who have at least one event that is not happening in the past) of the planned outage and started displaying a system-wide banner in the backend.
Saturday morning, we first wrote a checklist to work through over the day that we then followed. Checklists are a really powerful tool to keep calm even in stressful situations on production databases. If you don’t use checklists, make sure to try it out. Also, watch this amazing talk by Daniele Procida. Our checklist roughly looked like this:
-
Create a useful error page to show during the outage.
-
Ensure backups are running correctly for PostgreSQL. Test restoring a backup manually.
-
Rehearse the migration steps by migrating the staging system again.
-
Deploy a redis cluster to the new database nodes.
-
Find out and fix why the old redis cluster accumulated such a large memory footprint (this caused another two outages in the last weeks).
-
Configure a memory limit and eviction strategy for redis and introduce monitoring for Redis’ memory usage.
-
Test that the new redis cluster fails over correctly.
-
Take a break.
-
Deploy the new error page.
-
Wait for 22:00 UTC.
-
Disable monitoring.
-
Put a notice on status.pretix.eu and tweet the downtime.
-
Disable all backends in haproxy. Confirm that the error page is showing up.
-
Migrate production to PostgreSQL (see above for steps).
-
Restart all workers. Make sure production is running.
-
Configure production to use redis instead of RabbitMQ and move to new redis cluster.
-
Test failover of redis. Test failover of PostgreSQL. Kill a whole server to see how long it takes to recover.
-
Test if system performance is acceptable.
-
Enable all backends in haproxy.
-
Replace error page by default 503 message again.
-
Enable monitoring.
-
Update status page.
-
Watch the system and write this blogpost.
-
Sleep.
Further steps & Conclusion
Some issues that we had with MariaDB probably remain with PostgreSQL just the same. Despite all efforts with long timeouts and TCP keep-alive packets, the connection between App<>haproxy<>database occasionally dies. django-dbconn-retry looks like the solution but isn’t really considered stable right now.
The problem is a bit worse for Celery/Redis than for Django/PostgreSQL since the celery worker apparently start to hang in this case, so we still need to find a solution for this and monitor it closely. However, since our monitoring system buys a ticket every minute, there should always be some data on the wire and it wouldn’t go unnoticed for too long.
In conclusion, it has probably become clear that running a system that should fulfill certain availability constraints can be challenging even at a small scale. Performing a migration like this required a lot of work in preparation and a full day for executing, but was certainly worth it: The system is already running a lot faster and we’re looking into a bright future with PostgreSQL.
If you’d like to sell tickets for your event with a service which is as lovingly maintained and migrated like this one, make sure to try it out! :)